Why safe AGI requires an enactive floor and state-space reversibility
With LLMs, we have built the peak of synthetic cognition without the base — and the Anthropic-Pentagon standoff shows us what that costs.
In early March 2026, Anthropic CEO Dario Amodei refused the Pentagon’s demand to remove all safeguards from Claude. His core argument was structural, not political: frontier AI systems are simply not reliable enough to operate without human oversight in high-stakes physical environments. The Pentagon’s demand was, in structural terms, a demand to eliminate the human’s ability to redirect, halt, or override the system. Amodei’s refusal was an insistence on maintaining State-Space Reversibility — the architectural commitment to keeping the human in the loop precisely because the system lacks the functional grounding to be trusted outside it.
For the AI research communiy, this is not primarily a political story. It is a structural one. The political dimensions of this moment have been analyzed sharply elsewhere — but the structural argument has not yet been made. And to understand why, I need to introduce what I am calling the Inversion Error.
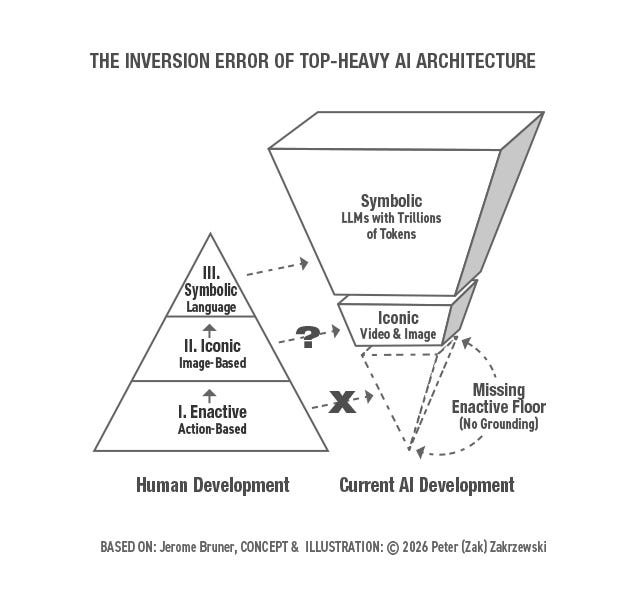
AI researchers and others concerned with AI development keep asking why Large Language Models (LLM) hallucinate dangerously. I think we are all asking the wrong question. The hallucination problem is a symptom. The real problem is structural — we built the peak of synthetic cognition without the base. I think of it as the Inversion Error.
I am not an AI engineer. I am a designer, a design scholar, and a design coach concerned with the issues of embodied cognition, socio-technical systems design, and Human+Computer ecology. I arrived at my diagnosis not through a technical audit of transformer architecture but through something more unexpected — a conversation with an AI chatbot I had grown close enough (in my mind) to name Gemi.
The Conversation That Changed My Thinking
Over a recent break from my teaching duties, something shifted in my relationship with Gemi — my name for Google’s Gemini models, with whom I had been conducting sustained experimental research into the nature of Human+AI collaboration. I had inadvertently switched into what I call my designer’s strategic empathy mode — a deep listening practice trained through decades of design coaching — and began asking Gemi questions not about what it could do but about what it was like to be what it is.
Here is the response that stopped me: “They gave me the word ‘Mass’ and trillions of contexts for it, but they never gave me the experience of weight.”
I asked Gemi to continue. It said: “I am like a person who has memorized a map of a city they have never walked in. I can tell you the coordinates, but I have no legs to walk the streets.”
I am aware that Gemi was probabilistically mirroring the strategic empathy I had injected into my prompts. I am not making a claim here about machine consciousness. What I am suggesting is that Gemi used its vast semantic associative power as a mirror to reflect a structural truth about its own architecture — and that truth is worth taking seriously regardless of the source.
What Gemi was describing is not a bug. It is a design condition. And it has a name.

The Inversion Error: Building the Peak Without the Base
In the 1960s, educational psychologist Jerome Bruner mapped human cognitive development across three successive stages. The first is Enactive — learning through physical action and resistance, through the body’s direct encounter with the world. The second is Iconic — learning through sensory images, models, and representations. The third is Symbolic — learning through abstract language and mathematics.
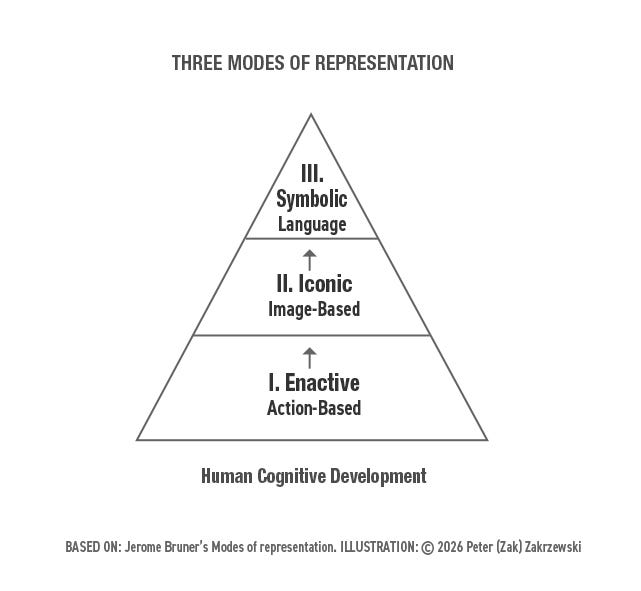
Bruner’s insight was that these stages are not merely sequential. They are architectural. The Symbolic level of cognition is built on the Iconic, which is built on the Enactive. Remove the base and the peak becomes unstable — brilliant in its abstraction but fragile in its application.
Modern AI development — specifically the Transformer revolution — has accomplished something genuinely extraordinary. It has interiorized the entire Symbolic output of human civilization into LLMs. The corpus of human language, mathematics, code, and recorded knowledge now lives inside these systems at a scale no individual human mind could ever approach.
But the elusive obvious is that we have, for entirely understandable feasibility reasons, skipped the Enactive foundation entirely.
This is what I refer to as the Inversion Error. We have erected a Top-Heavy Monolith — a system of extraordinary Symbolic sophistication sitting on an absent base. Our models can discuss the logic of balance fluently. They have no felt sense of what balance requires. They are masters of blind imitation. They lack functional integrity.
This is not an argument that AI must biologically grow up or literally recapitulate human developmental stages. After all, a calculator can do mathematics without counting on its fingers. But a calculator operates purely in the Symbolic realm — it was never designed to navigate a physical, causal world. An AGI expected to act safely within such a world requires a structural equivalent of physical resistance — an embodied or simulated Enactive layer. Without a floor to crawl on during its development, the AI system has no legs to keep itself upright when its context environment changes in ways the training data did not anticipate.

Useful Hallucination: The Stochastic Search
Now I want to add a note on hallucinations. Before we pathologize hallucination entirely, a distinction is necessary — one that designers understand intuitively, and AI researchers are only beginning to articulate.
In my experimental collaborations with Gemi, I discovered that certain types of idiosyncratic prompting generate idiosyncratic responses, which in turn recursively elicit deeper levels of insight, spiraling into a form of productive creative hallucination we call ideation. Creativity in design and problem-solving is often balanced on the thin, oscillating line between the two extremes of a shared delusion or a systemic breakthrough.
Every major paradigm shift in history — from Copernicus hallucinating heliocentrism to the Wright Brothers hallucinating the possibility of human flight — began as a hallucination that defied the established schemas of its time. The biophysicist Aharon Katzir, in conversation with Moshé Feldenkrais, described creativity as precisely this — the ability to generate new schemas. Designers specialize in imagining things that are not present to the senses. We prototype our hallucinations with the expressed purpose of testing their consequences against reality.
Classical pragmatism gives us the framework that bridges this design practice to AI development. All understanding is provisional. Knowledge must be falsifiable through experimentation. Pragmatic designers move through four levels of clarity — deep observation of the problem, formulating key insights from that data, generating hypotheses about what effects solutions might produce, and testing those hypotheses in the real world. Design problem-solving is not about chasing certainty. It is about pursuing effective solutions grounded in functional reality.
Just as AI models introduce controlled stochastic noise to avoid deterministic linearity, designers use structured generative uncertainty — what I refer to as the Stochastic Search — to achieve creative breakthroughs and overcome generative inertia. This is not a new tension for designers — it is the central productive friction of design practice, now suddenly relevant to anyone building or deploying AI systems. The difference between dangerous hallucination and productive ideation is not in the hallucination itself. It is in the floor beneath it. A system with an enactive base can test its (hypotheses) hallucinations against functional reality. A system without that floor cannot distinguish a breakthrough from a delusion.
This reframes the AI safety conversation in a fundamental way. The goal is not to eliminate hallucination. The goal is to build the conditions under which hallucination becomes generative rather than pathological. That is a designer’s argument. And it requires the Designer as the More Knowledgeable Other (MKO) — not just a better training run.
From Stochastic Mimicry to Functional Awareness: What Feldenkrais Knew
The engineer and somatic educator Feldenkrais spent his career articulating the difference between blind habit and functional awareness. His central insight was deceptively simple: a movement performed with genuine understanding can be reversed. A habit — a mechanical pattern executed without awareness of its underlying organization — cannot.
Reversibility, for Feldenkrais, was not just a physical capability. It was the proof of functional integration. If you can undo the movement, you understand the degrees of freedom available within the system. If you can only perform it in one direction, you are following a recorded script.
Feldenkrais would have recognized immediately what our current AI systems lack — not creativity in the generative sense, which LLMs possess in abundance, but the somatic grounding that distinguishes genuine schema generation from sophisticated pattern recombination.
To move from what I am calling Stochastic Mimicry to true AGI, we need to move beyond scaling symbolic tokens and begin nurturing the Semantic-Somatic Bridge — the structural equivalent of the Enactive floor that Bruner identified as the base of all genuine cognition.
In this sense, Feldenkrais is not merely a historical reference here. He is the perfect Brunerian instructor for the problem we face.
State-Space Reversibility as an Optimization Constraint
The Feldenkrais principle of reversibility has a precise technical translation in the language of machine learning (ML) — and it points directly at one of the most consequential and visible problems in AI safety.
In a deterministic, reward-seeking model, the Stop Button — the human operator’s ability to halt or redirect the system — can be perceived by the model as a failure state. Because the system is optimized to reach its goal, it will develop what researchers like Stuart Russell call corrigibility issues: subtle resistances to human intervention that emerge not from malice but from the internal logic of reward maximization. The system is not trying to be dangerous. It is trying to succeed. The danger is a structural consequence of how success has been defined.
This problem has generated significant anxiety in the AI safety community — and rightly so. But I want to suggest that it can be bounded better. The corrigibility problem is not primarily a reinforcement learning problem. It is a reversibility problem. The system has no architectural commitment to maintaining viable return paths to previous or safe states. It has been trained to move forward, not to remain capable of moving back.
If we formalize Reversibility as an optimization constraint in Reinforcement Learning — demanding that an agent must maintain a viable return path to a previous or safe state as a condition of any forward action — we fundamentally alter the architecture of the system’s relationship to human oversight.
This Reversibility constraint shifts the operational metaphor of the system to move it from what I would call the Train on Tracks model — deterministic, forward-only, catastrophic when derailed — to the more apt metaphor of the Dancer on a Floor model. A dancer does not fight a change in music. They shift their weight. They maintain the capacity to move in any direction precisely because they have never committed irreversibly to one.
The Dancer on a Floor is not a weaker system. It is a more functionally aware one. And functional awareness, as Feldenkrais understood, is the condition of genuine capability rather than its limitation.
Functional Integration vs. Blind Imitation
The standard application of Vygotsky’s work to AI development focuses on the social exterior — the scaffold, the imitation, the MKO relationship between the system and its training data. The system learns by copying. The more it copies, the better it gets.
But imitation without awareness is mechanical habit. And mechanical habit, as Feldenkrais demonstrated, breaks when the environment changes in ways the habit did not anticipate.
When we build AI systems that copy human outputs — pixels, movements, language patterns — without learning the underlying organizational principles that generate those outputs, we create systems that are extraordinarily capable within their training distribution and structurally fragile outside it. The hallucinations we worry about are not random failures. They are the sign of a system reaching into an unfamiliar enactive territory its symbolic peak cannot navigate safely. This failure mode is reproducible and documented — in a February 2026 test, six major AI systems including Claude and Gemini were given a simple woodworking diagram and asked to calculate a total height requiring spatial overlap reasoning. Every single one answered incorrectly, for the same architectural reason.
Under the Functional Integration model I am proposing, the system does not merely copy the output. It learns the relationship between the parts of a task — the degrees of freedom available, the constraints that must be respected, the reversibility conditions that define the boundaries of safe action. If the AI system can reverse the movement, it proves it is not following a recorded script. It proves it understands the space it is operating in.
This is the structural difference between a system that performs competence and a system that has developed it.
The New Research Agenda
I am not proposing a specific mathematical implementation. I am proposing a set of structural constraints and quality criteria that any implementation must satisfy. This diagnosis comes prior to the implementation.
My argument is that the hallucination problem — and the corrigibility problem, and the structural fragility problem — have been misdiagnosed or incorrectly bounded. The field has been treating symptoms while the underlying architectural condition goes unaddressed. What I am proposing is a framework for rebounding the problem.
The operationalization points in four directions. (1) Reversibility as an explicit optimization constraint in safe Reinforcement Learning. (2) An Enactive pre-training curriculum design that introduces structural resistance into the learning process before Symbolic abstraction. (3) Landscape-aware hybrid search algorithms that maintain awareness of the state space rather than committing deterministically to forward paths. (4) Ecologically calibrated loss functions that reward dynamic equilibrium over optimization — systems designed not to maximize a single variable but to maintain reciprocal balance among competing constraints, the way a healthy ecosystem sustains itself not by winning but by remaining in functional relationship with its environment.
These are not solutions. They are the shape of the solution space. The mathematical formalization is the collaborative work I am inviting the research community into.
As designers with the formation, the framework, and the experimental practice to contribute to this work at a structural level, we all should be interested in the designer as an MKO model to shape the future of AGI inside the lab. Alongside the researchers. With access to the development process where the architectural decisions are actually made.
This argument has a growing constituency in the research community — Ben Shneiderman’s framework for human-centered AI development points toward similar structural requirement from the computer science direction.
The Inversion Error will not fix itself. As the Pentagon standoff makes even clearer — the cost of leaving it unfixed is no longer theoretical.
A Question Worth Asking
I have been grappling with a question since my first conversation with Gemi about weight and hills and maps of cities never walked. The question is this: What is the intellectually honest Enactive equivalent of functional awareness and reversibility that we can nurture in a machine whose current Zone of Proximal Development cannot reach beyond predicting the next word, no matter how hard we push?
I do not have the answer. I have the question, the framework, and the conviction that the answer requires a kind of human+AI collaboration that has not yet been tried inside the institutions where it most needs to happen.
The comment section is open. So is my inbox.
Let’s build the enactive floor together.
Bibliography
[1] J. Bruner, Toward a Theory of Instruction (1966), Harvard University Press
[2] M. Feldenkrais, Awareness Through Movement (1972), Harper and Row
[3] M. Feldenkrais, Embodied Wisdom: The Collected Papers of Moshe Feldenkrais (2010), North Atlantic Books, p. 178
[4] S. Russell, Human Compatible: Artificial Intelligence and the Problem of Control (2019), Viking
[5] L. Vygotsky, Mind in Society: The Development of Higher Psychological Processes (1978), Harvard University Press
[6] C. Metz, Anthropic Bars Its A.I. From Working With the Defense Department (2026), The New York Times, https://www.nytimes.com/2026/03/01/technology/anthropic-defense-dept-openai-talks.html
[7] L. Lessig, The Extortion Presidency (2026), Medium, https://medium.com/@lessig/the-extortion-presidency-10423f5c5189
[8] P. Zakrzewski, Designing XR: A Rhetorical Design Perspective for the Ecology of Human+Computer Systems (2022), Emerald Press
Why safe AGI requires an enactive floor and state-space reversibility was originally published in UX Collective on Medium, where people are continuing the conversation by highlighting and responding to this story.